Beyond Kubernetes Operators: The Next Frontier of Infrastructure Orchestration

The cloud‑native world has spent the past few years marveling over Kubernetes operators. Born out of necessity to manage complex, stateful workloads on top of Kubernetes, operators promised to turn resources into applications by encoding the operational knowledge of a system into a custom controller.
They gave us a glimpse of what a self‑service platform could look like - and yet, as more teams adopted them, the limitations became harder to ignore.
This post unpacks my personal perspective on why operators emerged, how GitOps practices enabled their rise, and why the current crop of Kubernetes operators still leaves practitioners hungry for more. Finally, we'll explore how Bluebricks builds on these ideas to deliver a truly unified control plane for modern infrastructure.Why Operators Emerged
Kubernetes' declarative API was perfect for **stateless** microservices: you described the desired state in YAML and the control plane reconciled it. As organizations moved beyond stateless workloads toward databases, message queues and other stateful systems, they discovered that native resources were not enough.
A PostgreSQL cluster is more than a StatefulSet and a Service. It needs backup schedules, version upgrades, user management and fail-over logic.
The answer was to extend the control plane extend the control plane. Operators package domain-specific expertise into custom controllers that watch for custom resources and act on them.
GitOps: The Enabler of Operators
Operators alone aren't enough; they depend on a workflow that keeps the cluster in sync with its desired state.
GitOps provides that workflow. The reconciliation loop works by continuously observing the system's current state, comparing it to the desired state stored in version control, and adjusting the system to align them.
By making the desired state declarative and version‑controlled, operators can trust Git as the single source of truth and automatically converge toward it. Tools like Flux and Argo CD implement these loops and deliver custom resources to operators.
There is a catch for infrastructure when auto‑sync is enabled: once a change is merged, the controller will apply it. Without explicit gates, there is effectively no human monitor after merge. That is a blessing for speed and a risk for safety unless you add approvals or run manual‑sync for sensitive paths
Git defines what the system should look like; the operator's controller defines how to get there. This separation of concerns has driven huge adoption of operators in the past few years.
A Reality Check: Reviewing Today's Operators
Despite the promise, the reality of operating these systems varies dramatically. The marketing often glosses over the complexity of each solution. Here's a candid look at the current state of the most talked‑about operators, based on both community feedback and recent releases.
Crossplane: "The Universal Control Plane"
Often positioned as the Kubernetes control plane for "everything".
Use when
- You are building platform‑level abstractions and want infrastructure as typed APIs.
- You need namespaced multi‑tenancy and tight RBAC inside Kubernetes
You get
- Namespaced composites and managed resources by default in v2.0.
- Compositions that can include any Kubernetes resource.
- Declarative day‑two operations for tasks like backups and upgrades.
Trade‑offs
- No native plan or preview step; changes apply on drift.
- Provider maturity and coverage vary.
- Migration from Terraform is possible but rarely smooth.
- Steep learning curve to design useful compositions and glue.
Bottom line
Great for platform teams productizing infrastructure APIs. Expect slow time‑to‑value, uneven provider maturity, and governance friction without a plan step.
AWS Controllers for Kubernetes (ACK)
ACK lets you declare AWS services like S3, RDS and EC2 as Kubernetes resources.
Use when
- You are AWS‑first and want Kubernetes to be the front door to AWS services.
- You prefer declaring cloud resources in YAML alongside app manifests.
You get
- Native feel inside EKS with growing controller coverage.
- One workflow for application and AWS resource provisioning from the cluster.
Trade-offs
- No Terraform‑style plan; reconcile applies directly to AWS.
- IAM failure modes can be opaque and time‑consuming to debug.
Bottom Line
Good fit for AWS‑centric teams comfortable with reconcile‑driven changes. Audit‑heavy environments will miss plan and diff visibility.

Google Config Connector (KCC)
KCC manages GCP services from within Kubernetes.
Use when
- You are GCP‑centric and want Kubernetes‑native infrastructure workflows.
- You need namespaced multi‑tenancy aligned with GCP auth models.
You get
- Tight alignment with GCP resources and identities.
- A direct reconciler for some resources that improves speed and reliability.
Trade-offs
- Still reconciliation‑based with no plan or preview.
Bottom line
Natural for GCP shops that want a single control plane feel. As with the others, if you need previews and approvals, you must add your own gates.

Tofu Controller
Tofu Controller runs OpenTofu or Terraform via Flux in a GitOps loop.
Use when
- You want GitOps workflows but need to keep existing Terraform modules.
- You rely on plan and apply semantics for governance.
You get
- Reuse of Terraform modules without a full rewrite.
- Support for plan‑only and apply workflows integrated with Git.
Trade-offs
- More moving parts to operate: Flux plus Tofu and an extra controller.
- Multi‑layer troubleshooting can get intricate across systems.
Bottom line
A pragmatic bridge for teams standardizing on GitOps while preserving Terraform's plan and apply. Accept the complexity tax of blending ecosystems.
Azure Service Operator (ASO)
ASO exposes Azure resources as Kubernetes custom resources.
Use when
- You are Azure‑first and want Kubernetes‑aligned infrastructure management.
- You are prepared to track ASO releases closely.
You get
- Broad Azure surface area with active development.
- Kubernetes‑native CRDs for common Azure services.
Trade-offs
- Breaking changes appear in some releases and upgrades can require careful choreography.
- Expect to manage version pinning, secret migrations and sync behavior changes.
Bottom line
Works for Azure‑centric teams willing to absorb upgrade overhead and version churn. Operational discipline is a must.
Where Operators Fall Short
As you can see, every major cloud provider (and other companies) are striving to have their own controller, yet there is no one single working solution, nor massive adoption to any of them, and here is why I think it falls short:
No Preview (Plan) Phase
Unlike Terraform, operators immediately act on changes once the desired and actual states diverge. There is no plan or preview to show what will change before execution. Without this dry run, teams fly blind when making any modifications. Senior engineers I've worked with recall accidentally triggering destructive actions in production because there was no way to see a diff ahead of time. The lack of a plan reduces confidence, slows adoption and clashes with established change‑management processes.
Eventual consistency and unpredictability
Operators rely on reconciliation loops to converge toward the desired state. This model is robust but not deterministic across dependency chains: operations might complete instantly or take hours, and failures retry in the background. Explicit cross‑resource ordering is not guaranteed.
Observability Black Holes
When something goes wrong, operator logs are often verbose and unhelpful. There is rarely a unified view that shows the chain of resources being created, their relationships and their current status. Debugging requires piecing together CRD status fields, controller logs and external resource states. For teams without deep operator internals knowledge, this is a significant barrier.
Self‑Service Isn't Simple
Operators promise self‑service infrastructure, but their custom resource definitions often expose low‑level details that confuse developers.
Documentation gaps and cryptic error messages mean most teams still need a platform engineer to mediate operator usage and templatize CRDs in the form of Helm or Kustomize. Instead of democratizing infrastructure, operators sometimes centralize it in the hands of a few specialists.
Compliance and Risk Management Challenges
Many organizations have strict governance processes. Operators' reconciliation loops can modify infrastructure automatically, bypassing human approval - While can/should be gated by Git (When using GitOps), there is a common misalignment between who can do what and requires extra tuning to your git approval rules.
These challenges don't negate the innovation of operators, but they highlight that something more is required to manage complex, multi‑cloud environments at scale.
Chicken and egg
You need infrastructure to run the infrastructure control plane. VPCs, IAM roles and a Kubernetes cluster must exist before you can install an operator like Crossplane and let it manage the rest.
Security blast radius
When cloud permissions are bound to identities inside the cluster, the cluster becomes a critical trust boundary. For example, if pods can assume cloud roles, a compromised service account token can turn into cloud‑level access. Treat the cluster as a potential point of breach and harden accordingly.
And most importantly, the elephant in the cluster - there is no way to manage complex workflows across clouds, resources, and services.
Workflow Orchestration: Enter kro.run
The big cloud vendors get it, and hence they are backing up this project - Recognizing that operators manage single resources well but struggle with multi‑step workflows, the Kubernetes community has begun to explore dedicated workflow orchestrators.
kro.run is one such project. Described as a "Kube Resource Orchestrator," it lets platform teams define custom APIs that create multiple Kubernetes objects and the logical operations between them. The documentation notes that kro uses Common Expression Language (CEL) expressions to pass values between objects and "automatically calculates the order in which objects should be created" kro.run. In other words, kro introduces directed‑acyclic‑graph (DAG) orchestration to Kubernetes resources, letting users define dependencies and conditions so that resources are created in the right order.
While kro.run represents a significant step forward in workflow management – and is backed by vendors across AWS, Google Cloud and Azure – it still operates within Kubernetes' constraints and requires manual definition of graphs. Teams must build and maintain their DAGs and integrate them with existing IaC tooling.
Beyond Operators: How Bluebricks Solves the Real Problems
Bluebricks takes the ideas behind operators and workflow orchestrators and extends them into a comprehensive control plane for any infrastructure – Kubernetes, virtual machines, databases, or cloud services. Here's how:
Unified Control Plane for Any Resource
Instead of creating a custom resource for every new service, Bluebricks packages infrastructure code into immutable blueprints. A blueprint can wrap Terraform, OpenTofu, Ansible, Pulumi, Helm, CloudFormation, or virtually any code in a stateful way, combined with a proprietary orchestration definition..
Once published, blueprint versions are immutable, ensuring reproducibility and auditability.
Bluebricks orchestrates these blueprints across Kubernetes clusters, bare‑metal machines and cloud platforms, giving users a single API and CLI to manage everything.
Automated DAG‑Based Orchestration
Bluebricks orchestrates complex workflows using directed‑acyclic graphs, but it does the heavy lifting for you. When you deploy a stack of blueprints, the control plane analyzes their semantic relationships (inputs, outputs and dependencies) and automatically builds a DAG. It then executes steps in parallel where possible and serially where required, handling state propagation between resources.
Most importantly, execution is parallel and selective - it runs only what changed plus its dependencies. This reduces blast radius and shortens pipelines.
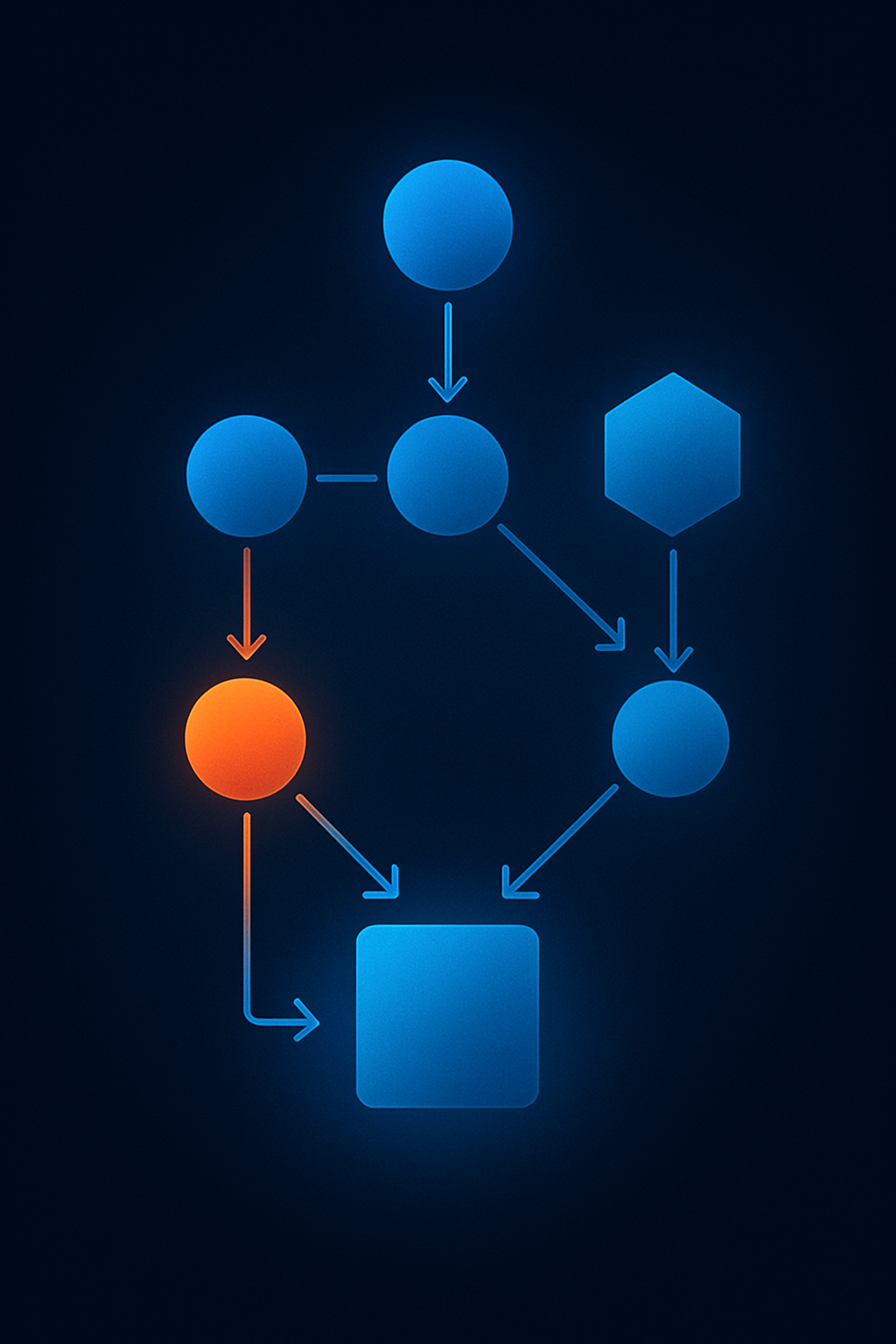
Rather than manually defining DAGs, the system automatically infers them based on blueprint relationships.
Plan and Apply Phases for Any IaC
Bluebricks reintroduces a two‑phase plan/apply model for all supported IaC tools in a unified manner. Before resources are modified, Bluebricks generates a plan, showing exactly what will be created, changed or destroyed.
Teams can require manual approvals for authorized owners or automatically proceed. This familiar safety net addresses one of the largest gaps with operators.
Semantic Relationships and Blast‑Radius Reduction
By modeling relationships between resources explicitly, Bluebricks provides a clear picture of your infrastructure's topology.
It can calculate the blast radius of a change, enforce property‑level policies and apply fine‑grained RBAC. This visibility also improves observability: users can see the status of each blueprint, its dependencies and any errors in one dashboard.
AI‑First Platform
Engineers can describe infrastructure needs in natural language and receive fully specified blueprints.
This AI‑assisted workflow sits on top of Bluebricks' control plane, ensuring that suggested changes still go through plans, approvals and policy checks.
Multi‑Cloud and Self‑Hosted Flexibility
Bluebricks is not limited to a SaaS model. Organizations can run the Bluebricks Deployment Controller inside their own clusters for complete control. The system works across AWS, GCP, Azure and on‑premises environments and is IaC‑agnostic. Whether your team uses Terraform, OpenTofu, Ansible or Helm, CloudFormation (yes, also CDK) or even its own custom suite of scripts, Bluebricks orchestrates them all.

Conclusion
Kubernetes operators sparked a revolution by embedding operational knowledge directly into the control plane.
They empowered teams to declare databases and message queues with YAML and let controllers handle the rest.
GitOps provided the reconciliation loop that turned declarative files into running systems octopus.com. Yet the more complex our infrastructures became, the more evident the limitations of this model became: lack of planning, unpredictable reconciliation, poor observability and governance challenges.
Workflow orchestrators like kro.run are emerging to fill some gaps, bringing DAG‑based workflows and cross‑service coordination kro.run. However, they still require manual graph definitions and operate solely within Kubernetes.
Bluebricks picks up where operators and workflow tools leave off. By unifying infrastructure management across Kubernetes and traditional environments, automating DAG orchestration, reintroducing plan/apply phases and layering on AI‑assisted workflows, Bluebricks offers a truly atomic approach to infrastructure. It provides the control and visibility that operators lack, while preserving the GitOps principles of declarative configuration and continuous reconciliation. For platform engineers seeking to move beyond these limitations, we've designed Bluebricks to represent what we believe infrastructure management should look like in the modern era.






